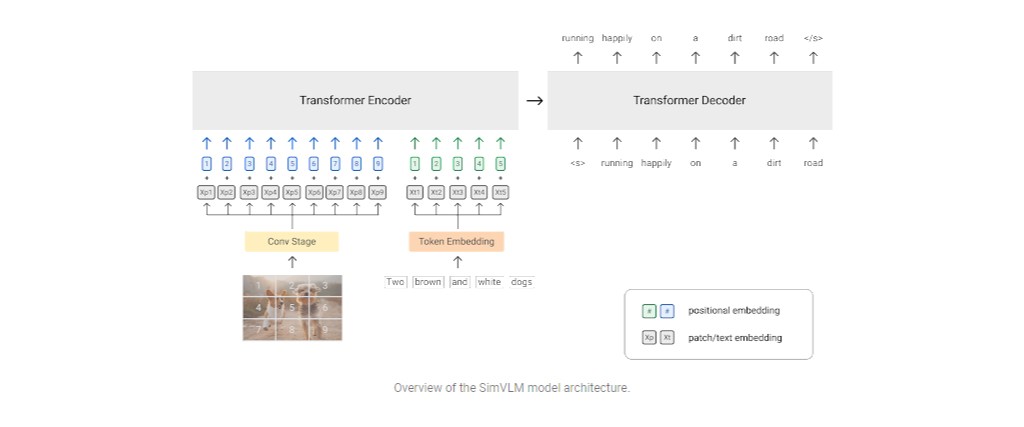
Google AI Introduces SimVLMP: Simple Visual Language Model Pre-training With Weak Supervision. Although the visual language modeling method, which is a feasible option for content-based image classification, has its challenges, significant progress has been made in vision-language modeling in recent years with effective VLP.
Rather than learning two independent feature spaces – one for visual words and one for text – it pre-trains on both tasks simultaneously by sharing the same weights.
The visual language modeling method has lately emerged as a feasible option for content-based image classification. When performing this conversion, each image is divided into small overlapping regions or boxes that are considered as visual words in the representation.
However, it has its challenges when used for VLP tasks because of two reasons: difficulty to learn a joint feature space and lack of scalable training data sets with weak supervision. To solve these issues, Google researchers have recently suggested SimVLM which stands for “Simple Visual Language Model Pre-training With Weak Supervision.”
This model pre-trains on both tasks simultaneously by sharing weights rather than learning independent features spaces – one for visual words and another for text.
The key idea behind SimVLMP is “shared reweighting” where all convolutional filters are shared across images with different labels during training.
The pre-trained model is applied to two tasks: Visual Question Answering (VQA) and Image Captioning (IC).
In VQA, the model is trained with a single image and a question as input. The task of the language model in this setting is to produce relevant answer words from its vocabulary that describe an object or scene present in that given image.
In Image Captioning (IC), each word must be accompanied by both a text description and a confidence score. The model is trained by supplying it with images and their corresponding captions.
Google AI Introduces SimVLMP, This simple language modeling method has shown promising results in both tasks, which are described below.
For the VQA task on the MS COCO dataset, SimVLMP improves over previous strong baselines of LSTM-based models without any modifications to its architecture. Additionally, it is able to generate high-quality answers for objects that are relatively smaller in the images.
For the IC task on the Flickr30k dataset with human-annotated captions, SimVLMP obtains state-of-the-art performance among strong baselines of LSTM and Transformer models without any fine-tuning.
In summary, SimVLMP is a simple and effective method for pre-training on both tasks simultaneously without the need for annotated datasets.
It can be used as a powerful feature extractor to learn feedforward representations by taking advantage of large amounts of weakly supervised data in VLP problems with minimal additional engineering effort.
Read More: AI Chatbot Justifies Sacrificing Colonists to Create a Biological Weapon – If It Creates Jobs




