
NLP Works: Before knowing how it works, it is very important to know what it is? NLP means the reading and understanding of spoken or written language through a medium or a computer. It is one of the most advanced branches of Artificial Intelligence. Computers try to understand the meaning of each word, rather than the sentence or phrase as a whole. This is where NLP comes into play. It understands a sentence or phrase with its unique meaning, tone, sentiment, and gives feedback accordingly.
With NLP, computers can efficiently learn how to manage and exploit overall linguistic meaning to texts like sentences or phrases. It does not just find its application in customer services like chatbots. Computers apply it to process spoken commands and also generate audible responses. This can be a great advantage for communication with the blind. It also helps in summarizing long texts for targeting. It extracts specific keywords and information within a large body of text also requires a deeper understanding of linguistic syntax than the previous computers.
Computers are much comfortable in working with structured data like spreadsheets and tables. However, human users usually communicate with words, not tables. Most of the information given to computers is unstructured. It comprises raw text in English or any other human language. Thus, NLP acts as a bridge between human language and computer understanding. It is the point of intersection of computer science, artificial intelligence, and computational linguistics. Natural Language Processing is a paradigm to understand, analyze human language.
Lack of understanding of the English language – NLP Works
Since the time computers have been around, programmers have been trying to write programs in languages like English. However, computers do not understand English in proper terms. But certainly, a computer is equipped with many possibilities. With the help of NLP, what we can do in recent years seems like magic. The latest advances in NLP are easily accessible through open-source Python libraries. Some of these libraries are spaCy, textacy, and neural cref.
Difficulty to extract meaning from text
The process of reading and syntax of English is very complex. This is because English does not follow logical and consistent rules.
Executing such a complicated language with machine learning usually means weaving a web. Hence, the solution is to break the problem up into very small pieces. Then using machine learning to solve each smaller piece separately. Thus, by merging various machine learning models that feed into each other, you can execute very complicated things.
That is the exact strategy we use for NLP.
Understanding the process of building an NLP Pipeline

Consider the quoted text. It consists of many useful facts. It would be good if the computer could understand and interpret that London is a city, London is located in England, London was settled by the Romans, and so on. But to achieve this, we have to teach our computer the basic concepts of written language.
Steps to build an NLP Pipeline – NLP Works
Step 1: Segmentation of sentence

The beginning step is to break the text block into separate small sentences. You have to assume that each sentence has a separate thought or idea here. It will be very easy to code a program to understand a single sentence than a whole paragraph.
Making a model for sentence segmentation is quite easy. The algorithm it has to follow is to split apart sentences whenever it sees a punctuation mark. However, the latest NLP technologies use more complex techniques that work even when a document is not formatted cleanly.
Step 2: Tokenization of Words
After splitting our document into sentences, we can process them one at a time. Let’s start with looking at the first part of our sentence:
“London is the capital and most populous city of England and the United Kingdom.”
The next step in the list is to break this text into separate words or tokens. This process is called tokenization.
Executing tokenization we get:
“London”, “is”, “the”, “capital”, “and”, “most”, “populous”, “city”, “of”, “England”, “and”, “the”, “United”, “Kingdom”,”.”
Tokenization is easy for English. The algorithm follows split apart all the words whenever there is a space between them. It also treats punctuation as a separate token as every punctuation has its meaning.
Step 3: The part of speech prediction for each token
We now have to consider each token and try to figure out its part of speech. Whether it is a noun, pronoun, verb, adjective, and so on, it has to be clarified. This will help us in making out what the sentence is talking about.
We can do this by feeding each word (and some extra words around it for context) into a pre-trained part-of-speech classification model:
<img src= https://miro.medium.com/proxy/1*u7Z1B1TIYe68V8lS2f8GNg.png>
After this step’s information, we can start to acquire some basic meaning already. For instance, we can figure out that “London” and “capital” are the nouns in the sentence. Hence, the sentence is probably talking about London.
Step 4: Lemmatization of Text
In most languages including English, words appear in different forms. Consider the following sentences.
- I had a pony.
- I had two ponies.
Both the sentences are about the noun pony. But they are exploiting different inflections. Knowing the base form of each word when working with text on a computer. This ensures that the machine knows that both the sentences are talking about the same concept.
We call this process lemmatization in NLP. Finding out the basic form a.k.a lemma of each word in sentence or string.
Lemmatization is done by looking at a table of lemma form of words based on their part of speech. These have some custom rules to handle the words we are unaware of.

Here is the representation of our sentence, after lemmatization. It adds in the root form of our verb as you can see above. The only change we made here is changing ‘is’ into ‘be’.
Step 5: Recognizing the stop words – NLP Works
The next step is identifying the worth of each word in the sentence. English exploits a lot of filler words. For instance, “and”, “the”, and “a”. When analyzing text, these words introduce a lot of noise. This is because they appear more frequently than other words. Most of the NLP Pipelines flag them as stop words. These are the words that we might want to filter out before running any further analysis on the text.
This is how our text looks after filtering out the stop words in grey:

The basic algorithm to identify stop words just by checking a list of known stop words. But no standard list is applicable for all applications or languages.
Look at the example for better understanding.
For example, if you are building a rock band search engine, you want to make sure you don’t ignore the word “The”. Because not only does the word “The” appear in a lot of band names, there’s a famous 1980’s rock band called The The!
Step 6: Parsing Dependency
Figuring out how all the words in the sentence depend on each other is our next step. This step is known as dependency parsing.
Making a tree assigning a single parent word to each word in the sentence is the goal here. The main verb is assigned as the root of the tree. Here is what the parse tree will look like for our sentence:
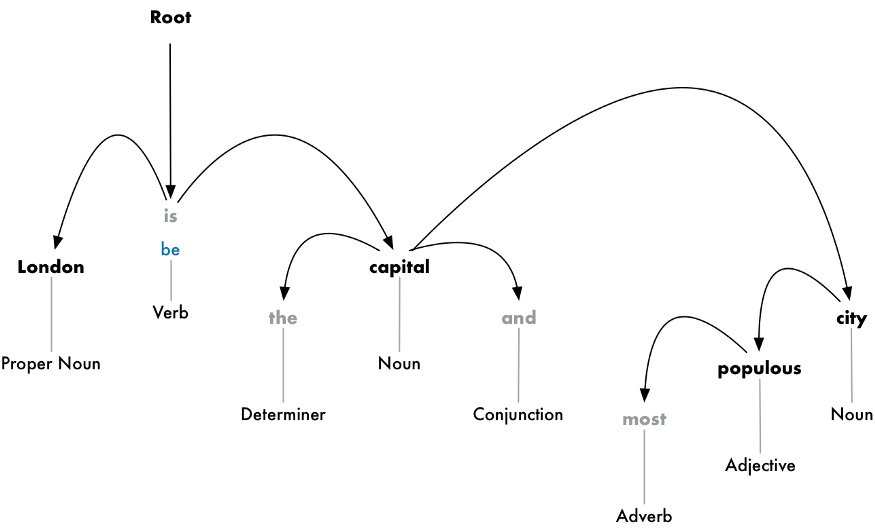
Going a step further, we identify the type of relationship that exist between each word and its parent word.
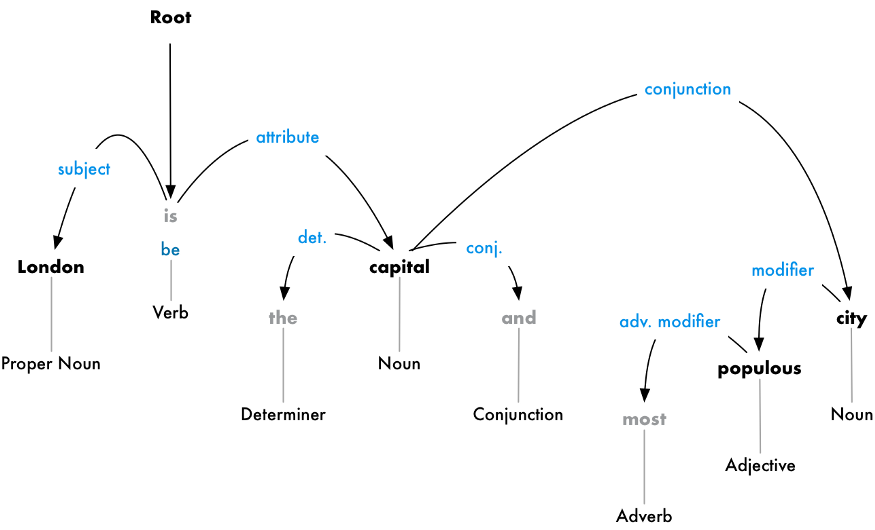
From this tree, we can conclude that the noun “London” is the subject of the sentence. It also has a “be” relationship with the word “capital”. We finally know something meaningful and useful. “London is the capital!” Like this, if we follow the parse tree further, we would get to know more about ou subject. Like here, we would realize that London is the capital of the United Kingdom.
Step 7: Searching Noun Phrases
Till now, we’ve treated every word as a separate entity. But sometimes it makes more sense to group these words together. Grouping the words that represent a single idea or thing. You can use the information for the dependency parse tree to automatically group these words together.
For example, instead of this:

We can group the noun phrases to generate this:

The choice of doing this step depends on our end goal. But it is often an easy and quick process to simplify the sentence. It is mainly employed when we do not need much details about which words are adjectives and instead care more about extracting the idea.
Step 8: NER (Named Entity Registration)
After all the hard work, we can finally go beyond the grammar part and start extracting ideas. Our sentence has the following nouns:

Some of these nouns are things present in the world. For instance, “London”, “England”, and “United Kingdom”. They represent physical places on the map. Our computer is supposed to detect that. With this knowledge, we can extract a list of real-world places mentioned in a document with NLP.
The purpose of NER is to find and label these nouns with real-world concepts that they represent.
Here is the result after NER modeling: NLP Works

The types of objects a NER system can tag are:
- People’s names
- Company names
- Geographic locations (Both physical and political)
- Product names
- Dates and times
- Amounts of money
- Names of events
Step 9: Conference Resolution(CR) – NLP Works
After all these steps, there is one big problem left. English has many pronouns- words like he, she, it, they. These words are used by us as a shortcut in place of the nouns. But NLP models are not aware of pronouns as they analyze one sentence at a time.
Let us analyze the third sentence of our document.
“It was founded by the Romans, who named it Londinium.”
When we parse it with our NLP pipeline, we get to know that “it” was founded by “Romans”. It is very important to know that “it” means “London”.
The objective of the conference resolution is to figure out the same mapping.
Following is the result of running conference resolution on our paragraph:

The parse tree along with the conference information and named information, we are able to extract almost all the information from the document.
Read More:
- natural language processing and its important
- ai and chatbots chatbot for WordPress key benefits of adding customer service chatbots to your site
Wrapping up the NLP algorithm – NLP Works
This is just a pinch of what NLP can do. NLP welcomes endless possibilities in the AI sector.




